



Inferless January Newsletter : Mixtral Experiments, Docker Integration, Phi 2 Fine-tuning Guide, CLI Enhancements, and more!

Hello Inferless Community! 🎉
We're excited to bring you a host of new resources and platform updates. For those new here, at Inferless we specialize in deploying custom machine learning models in a serverless environment. Our approach ensures minimal cold starts, making GPU inference workloads both speedy and cost-effective.
💡From Inferless Blog: Save upto 50% cost by Implementing Fractional GPUs in Kubernetes.
Maximize your resources and save up to 50% on costs by implementing fractional GPUs in Kubernetes. Our comprehensive tutorial showcases how to divide a single GPU into up to seven smaller GPUs, each with independent memory, cache, and streaming multiprocessors.
This guide, featured on the Hugging Face Blog, is ideal for Machine Learning Engineers, Data Scientists, and AI researchers. It includes a step-by-step approach, detailed setup instructions, and insights into the capabilities of Aliyun Scheduler.

Key Highlights of the blog:
Techniques for deploying containers with shared GPU resources.
Comparative analysis of various methods.
Detailed instructions on utilizing the Aliyun Gpushare Scheduler Extender.
You can read the detailed tutorial here.
🚀 Inferless Platform : New Features & Enhancements:
Docker-Based Model Import: Introducing support for any Docker image and DockerFile, enhancing model deployment flexibility. Visit our Docker integration documentation for more details.

Removal of Input/Output JSON: We've eliminated the need for adding Input/Output JSON in the Inferless console. You can now conveniently configure I/O parameters within your app.py code. For more details, please refer to our Input/Output Schema documentation.
Enhanced Support for CLI Users: If you are using CLI based deployments, you can now seamlessly push data to Inferless volumes via CLI, enabling direct access to the data across all replica containers. For more details, please refer to our CLI Import documentation and video tutorial here.

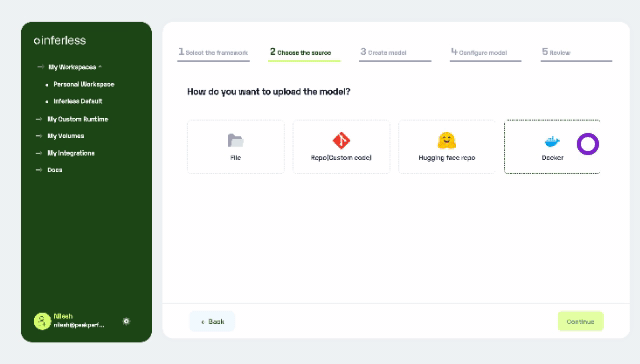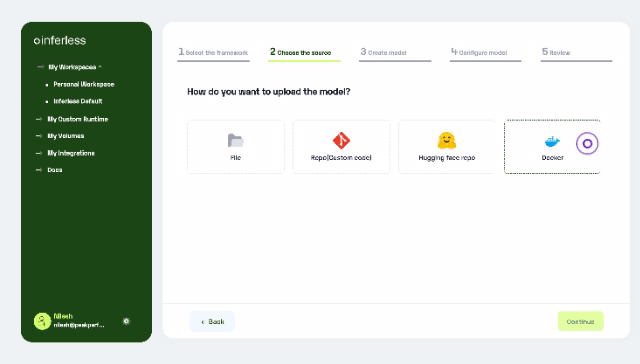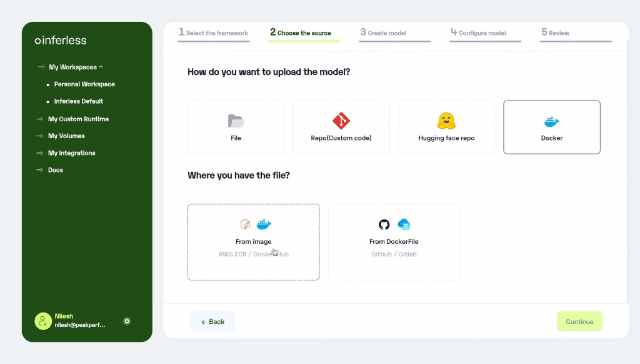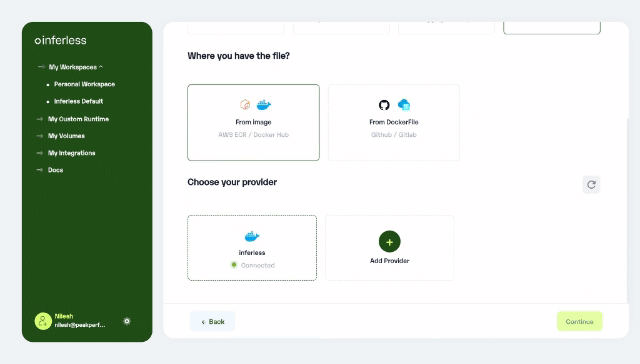
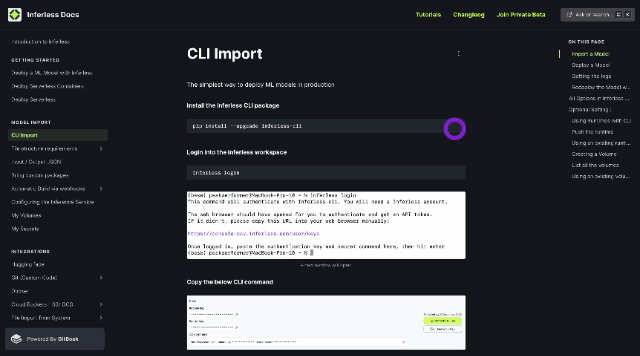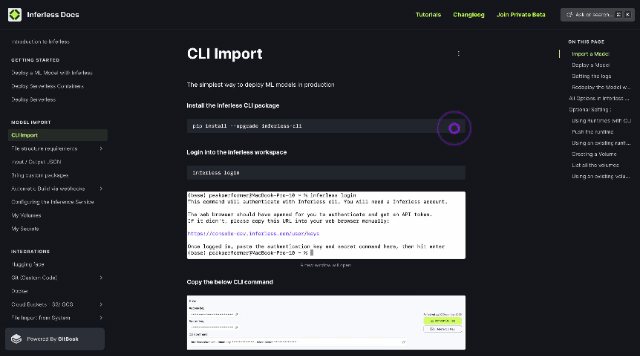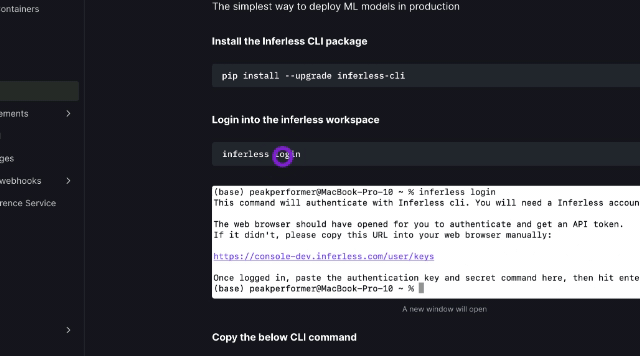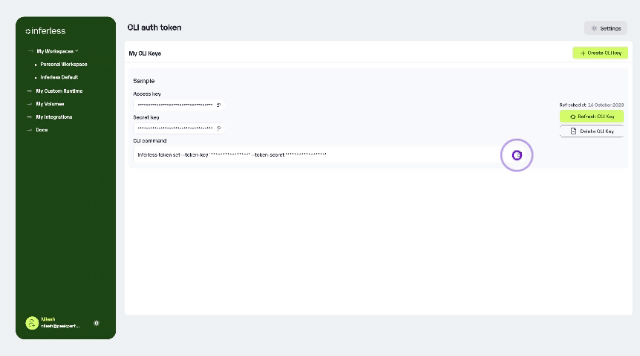
Apart from these enhancements, Users can now manage docker imports via webhook support, direct GitHub repository search from the console, and enhanced security upgrades for improved performance and safety. For more details, Check out our Changelog here.
🌟 Inferless Community Highlights:
Experiments with Mixtral: Our exploration with Mixtral 8x7B utilized PyTorch optimizations, vLLM, AutoGPTQ, and HQQ. We achieved a token generation rate of 52.03 token/sec with an 8-bit quantized model.

Explore our detailed guide for more insights here.
Tutorial on Fine-tuning, Quantization & Inference for Phi 2 model:
Here is a detailed tutorial & colab notebook showing how to fine-tune, quantize and deploy Phi-2 model, a 2.7 billion parameter language model by Microsoft Research which outperforms the 7B Mistral and 13B Llama-2 models in various benchmarks. When deployed on Inferless, you can expect ~7 seconds of cold-start and ~21.34 tokens/second
Check out the Tutorial here.
Spotlight on TenyxChat: Celebrating the success of our early adopters Tenyx with their TenyxChat series, now the best-performing open-source chat model on MT_Bench. Surpassing GPT-3.5 turbo, this achievement comes through fine-tuning the Mixtral_8x7B model with Tenyx's advanced continual learning technology. Read more about this breakthrough in the VentureBeat article. Discover and deploy TenyxChat on the Inferless platform today.
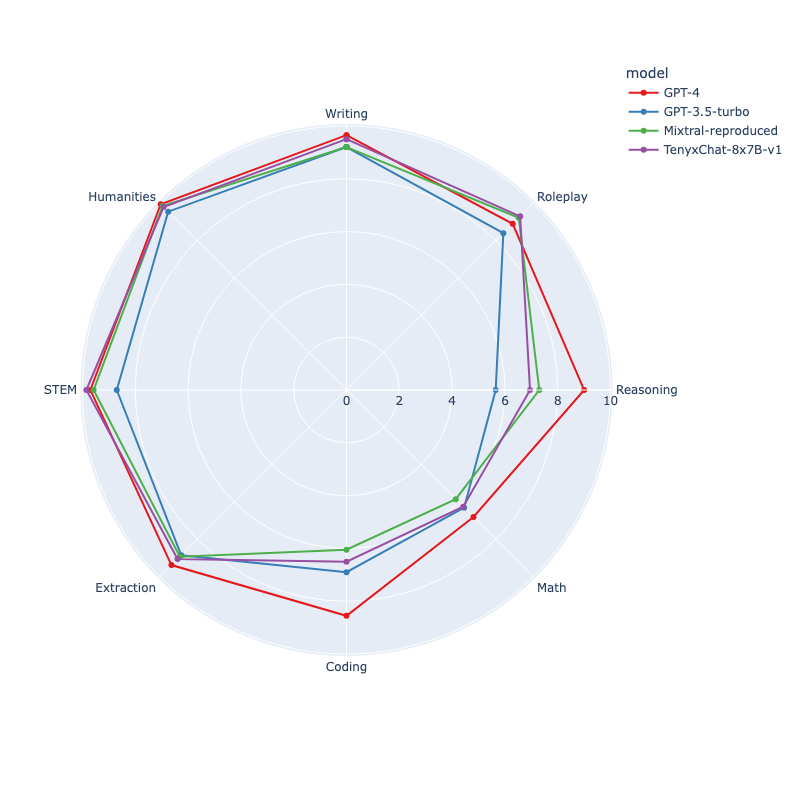
Check out Tenyx deployment Tutorial on Inferless platform below:
- TenyxChat 7B
- TenyxChat-8x7B-v1


That's it for this month! If you have questions, ideas, or just want to say hi, feel free to reach out. We love hearing from you. Until our next exciting update! 🌐💡👩💻